This is Part II in a two-part series. Part I covers the Trade Me application architecture.
Tim’s second lot of questions are about our dev tools and process:
Q: Any third party tools in the software or the dev/management process?
Q: What source control software do you use, and how do you use it?
Q: How do you manage roll outs? Dev/Staging/Live?
Q: Do you use pair programming, or adopt any other methodologies from the agile world?
The answers to these questions are just a snapshot, capturing how we do things today (early in April, 2007).
I go far enough back to remember when our “development environment” was Jessi’s PC (Jessi at that stage was our entire Customer Service department!) Back then there was no source control as such, we all shared a single set of source files. To deploy a change we would simply copy the relevant ASP files directly onto the live web server and then quickly make the associated database changes.
Somehow it worked!
Ever since then we’ve been constantly tweaking the tools and processes we use, to accommodate a growing team and a growing site. As our application and environment has evolved and become more complex our tools and process have had to change also.
This change will continue, I’m sure. So, it will be interesting to come back to this post in another 8 years and see if the things I describe below sound as ridiculous then as the things I described above do now.
Also, the standard disclaimer applies to these ideas: what makes sense for us, in our environment and with our site, may not make sense to you in yours. So, please apply your common sense.
Tools
Our developers use Visual Studio as their IDE and Visual SourceSafe for source control.
All of our .NET application code and all of our stored procedures are kept in a SourceSafe project. Developers tend to work in Visual Studio and use the integration with SourceSafe to check files in and out etc.
Thus far we’ve used an exclusive lock approach to source control. So, a developer will check out the file they need to make changes to and hold a lock over that file until the changes are deployed.
However, as the team gets bigger this approach has started to run into problems - for example, where multiple developers are working on changes together, or where larger changes need to be made causing key files to be blocked for longer periods.
To get around these issues, we’re increasingly working on local copies of files and only checking those files out and merging in their changes later. I imagine we will shortly switch to an edit-merge-commit approach, and that will require us to look again at alternative source control tools (e.g. SourceGear’s Vault, Microsoft’s Visual Studio Team System or perhaps Subversion - we’d be interested to hear from anybody who’s had experience with any of these).
Release Manager
At the centre of our dev + test process is a tool we’ve built ourselves called the ‘Release Manager'.
This incorporates a simple task management tool, where tasks can be described and assigned to individual developers and testers. It also hooks into source control, and allows a developer to associate source code changes with the task they are working on.
This group of files, which we call a ‘package’, may include ASPX files, VB class files as well as scripts to create or replace stored procedures in the database.
The tool also incorporates reports which help us track tasks as they progress through the dev + test process. These are built using SQL Reporting Services.
Environments
We have four environments:
- Dev: this includes a shared database instance and local web servers for each developer.
- Test: this includes a production-like database (actually databases, as we now have multiple instances in production) and a separate web server.
- Stage: our pre-production environment, again with it’s own web server
- Production: our live site, which actually incorporates two environments currently, one in Wellington and one in Auckland.
Developers typically work on changes individually. We have a code-review process, so any code changes have two sets of eyes over them before they hit test.
Once a code change is completed, the developer will create the package in Release Manager and set the task to be ‘ready to test’ so it appears on the radar of the test team.
We have a web-based deployment tool which testers can use to deploy one or more packages into the test environment. This involves some Nant build scripts which get the source files for the selected packages, copy these into the test environment and then build the .NET assemblies on the test server. The build script also executes any associated database changes that are included, and then updates the status of the package/s to ‘in test'.
The deploy tool is able to use the data from Release Manager to identify any dependencies between packages. Where dependencies exist we’re forced to deploy packages in a certain order, but in the general case we’re able to deploy packages independently of each other, which provides a great degree of flexibility and allows us to respond quickly where required (e.g. when there is an urgent bug fix required).
Production
Once a package has been tested the test team use the same deploy tool to move the package into the stage environment ready for go-live.
From there the responsibility switches to the platform team, who manage our production web servers. They have automated scripts, again built using Nant, which deploy from stage to our production environment/s. These scripts update configuration files then copy the required production files to the various web server locations. It also manages the execution of database scripts. The idea is to get everything as close to the brink as possible (which is the time consuming part of the deploy process) and then tip everything over the edge as quickly as possible, so as to minimise disruption to the site.
Typically we do two production releases each day, although this number varies (up and down) depending on the specific packages. In most cases these releases are done without taking the site offline.
The bigger picture
Our dev + test process is just one part of a much bigger product management process, which is roughly represented by the diagram below (click for a larger view):
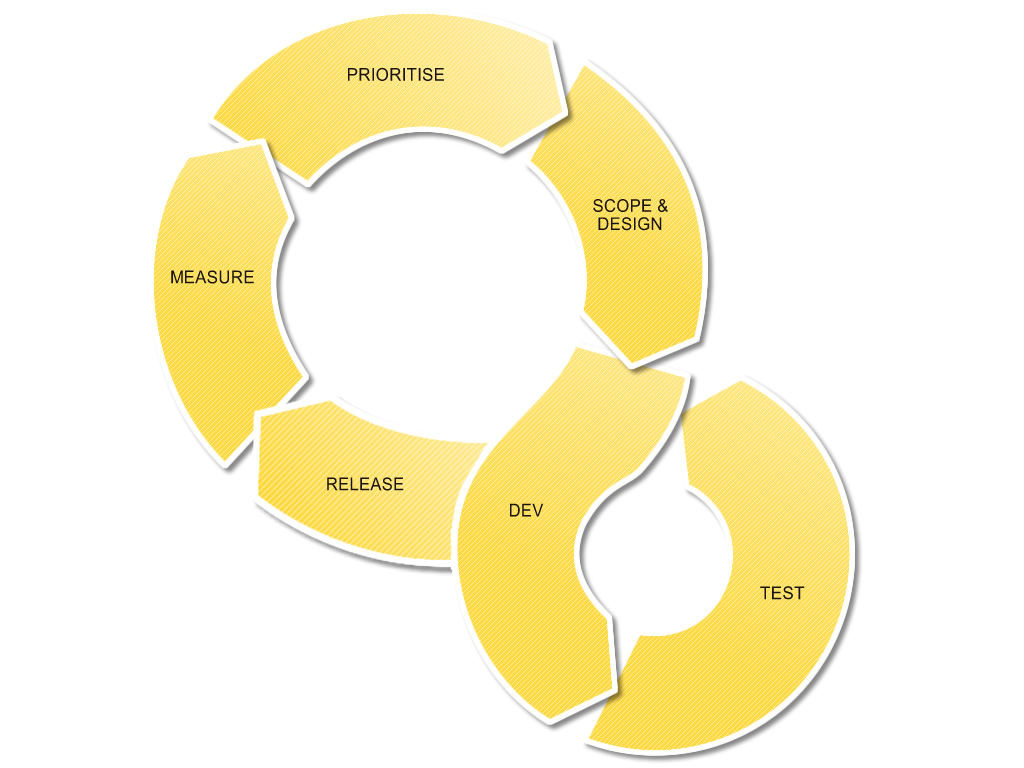
The other parts of this process are probably fodder for a separate post, but it’s important to note that there is a loop involved here.
Most of the changes we make to the site are influenced heavily by previous changes. In many cases very recent changes. This only works like it does because our process allows us to iterate around this loop quickly and often.
While we don’t follow any formal agile methodology, our process is definitely lightweight. We don’t produce lots of documentation, which is not to say that we don’t design changes up-front, just that we don’t spend too much time translating that thinking into large documents (it’s not uncommon for screen designs to be whiteboard printouts for example).
While we do make larger changes from time to time (for example, the DVD release which went out last week) the vast majority of changes we make are small and seemingly insignificant. Again, this only works because each of these small changes is able to flow through with minimal friction added by the tools and processes.
I’d also hate to give you the impression that this process is perfect. There is massive room for improvement. The challenge for us is to continue to look for these opportunities.
